Aqui está a apresentação do nosso projeto e links importantes
Pode levar até 30 segundos no primeiro acesso a plataforma pois a máquina que à hospeda pode estar dormente.

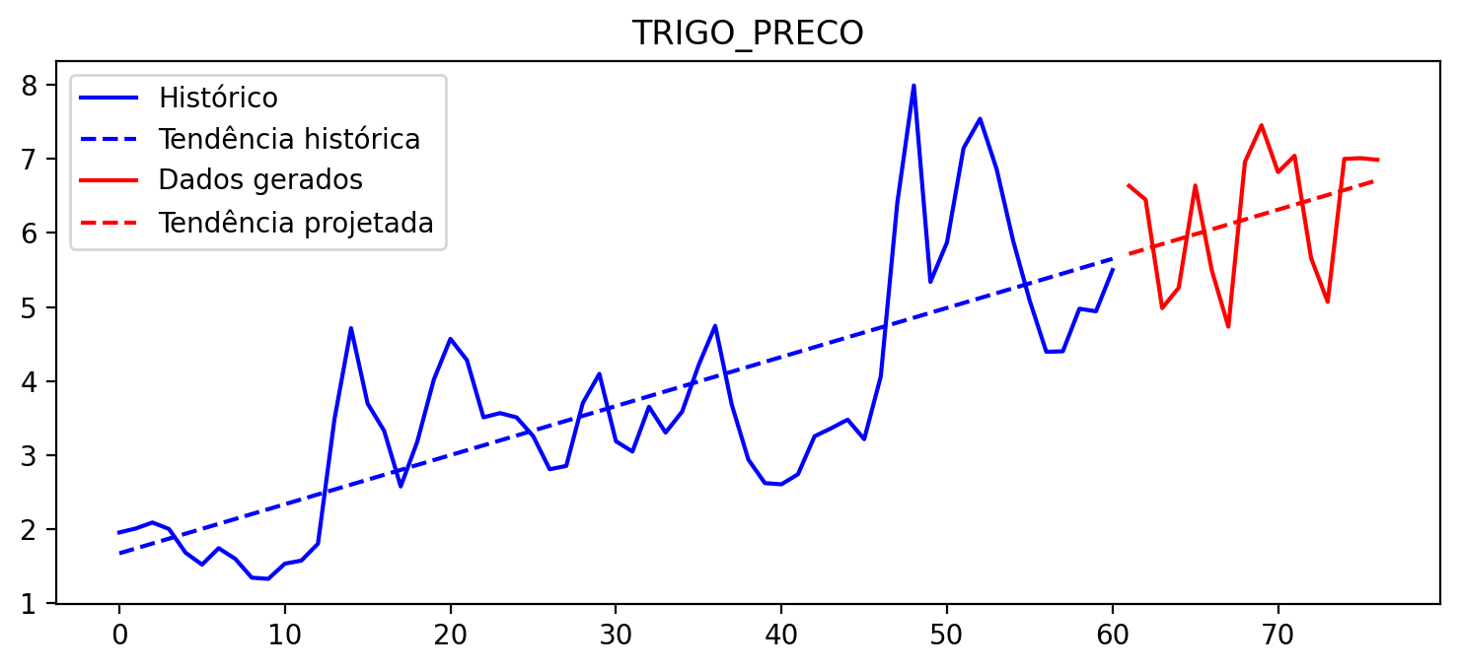
Desenvolver um modelo de machine learning capaz de prever o comportamento do preço da commodity agrícola trigo, utilizando dados climáticos e econômicos históricos. O modelo serve como auxílio para investidores que já investem ou gostariam de começar a investir nessa commodity. A interação com o modelo é feita a partir de uma aplicação web interativa.
Para criarmos um modelo satisfatório, coletamos diversos dados para o seguinte grupo de países que se destacam na produção, importação ou exportação do trigo: Austrália, Brasil, Canadá, China, Alemanha, Egito, França, Grã-Bretanha, Indonésia, Índia, Filipinas, Rússia, Turquia e Estados Unidos.
Dentre os dados coletados, estão:
Indicadores econômicos, de pobreza e desigualdade social e populacionais para analisar a tendência de aumento ou diminuição do consumo de itens básicos como o trigo:
Indicadores que influenciam na produtividade agrícola:
Indicadores históricos da commodity em análise:
Além destes, também foi incluído no modelo uma variável com o preço de outra commodity que interfere diretamente no valor de todas as outras: o petróleo.
Pode levar até 30 segundos no primeiro acesso a plataforma pois a máquina que à hospeda pode estar dormente.

Bacharel e Mestre em Ciências em Engenharia Mecânica pela Universidade Federal de Itajubá. Portfólio: guilhermeaoliver.github.ior

Desenvolvedora e Analista de Dados, através de Dashboards auxilio stakeholders em tomada de decisões, operações e identificando brechas.

Engenheiro de equipamentos experiente com um histórico comprovado de trabalho na indústria de petróleo e energia. Entusiasta de ciência de dados e aprendizado de máquina.

Engenheiro e desenvolvedor de dados com experiência em computação em nuvem (AWS, GCP), desenvolvimento e manutenção de pipelines, data lakes e data warehouses.
Existe uma vasta quantidade de datasets e dados disponíveis de forma gratuita pela internet. Porém, a coleta e limpeza de dados ocupou a maior parte do tempo do projeto, o que mostra sua importância.
Existem diversos modelos de machine learning que podem ser utilizados para uma mesma aplicação. Automatizar os testes iniciais para cobrir todos os modelos disponíveis foi uma excelente iniciativa que nos permitiu chegar mais facilmente ao melhor modelo.
Os GCMs (Global Climate Models) são cálculos feitos por clusters de computadores que consideram inúmeros fatores químicos e físicos da atmosfera e dos oceanos, e fatores comportamentais da sociedade. Com estes cálculos pode-se prever possíveis futuros. A princípio consideramos utilizar os dados climáticos já com as projeções disponíveis no world bank para as próximas décadas. Contudo, analisando os dados, descobrimos que existem diferentes tipos de GCMs que por sua vez tem diferentes tipos de cenários, como por exemplo A2 e B1, que consideram diversos comportamentos da sociedade capazes de impactar diretamente nas mudanças climáticas. Portanto, por não haver um padrão único para os GCMS optamos por usar apenas os dados históricos.
Aprendemos sobre as técnicas de interpolação para preencher valores desconhecidos. Utilizamos a função interpolate() com o pandas na análise dos dados de crescimento da população, pobreza e desigualdade.
Conhecemos o framework Streamlit utilizado para a criação de apps. https://streamlit.io/ e o utilizamos para fazer o deploy de nosso projeto.




Fizemos o deploy com a versão gratuita do Heroku e segue abaixo os preços para as versões pagas.
Para mais informações sobre preços clique aqui.Não foram encontrados datasets gratuitos. Porém, optou-se por descartar esta variável pela altíssima correlação com o preço do petróleo, dado que em 2019 aproximadamente 84% de toda a energia gerada no mundo vinha de combustíveis fósseis.